پایگاه داده Nebula Graph چیست؟

- بهمن 25, 1401
- 0
- ملیحه ایزی
پایگاه داده گراف چیست؟
پایگاه داده گراف، مانند NebulaGraph، پایگاه داده ای است که در ذخیره سازی شبکه های نموداری گسترده و بازیابی اطلاعات از آنها تخصص دارد. این به طور موثر داده ها را به عنوان رئوس (گره ها) و لبه ها (روابط) در نمودارهای دارای برچسب ذخیره می کند. ویژگی ها را می توان هم به راس ها و هم به لبه ها متصل کرد. هر رأس می تواند یک یا چند تگ (برچسب) داشته باشد.

پایگاه داده های گراف برای ذخیره انواع مدل های داده انتزاعی و نیز واقعی مناسب هستند. سیستمهای مدلسازی مانند پایگاههای داده رابطهای، روابط بین موجودیتها را استخراج میکنند و آنها را به تنهایی در ستونهای جدول فشرده میکنند و انواع و ویژگیهای آنها در ستونهای دیگر یا حتی جداول دیگر ذخیره میشوند. این امر مدیریت داده ها را زمان بر و مقرون به صرفه می کند.
پایگاه داده Nebula Graph
NebulaGraph، به عنوان یک پایگاه داده گراف بومی معمولی، به شما این امکان را می دهد که روابط غنی را به صورت لبه هایی با انواع یال ها و ویژگی های مستقیماً متصل به آنها ذخیره کنید.
این پایگاه داده مبتنی (Apache) بر گراف میتواندصدها میلیارد رأس و تریلیون ها یال را میزبانی کند و پرس و جوهایی را با تأخیر میلی ثانیه ارائه دهد. با این فناوری امکان پردازش گراف به صورت ابری فراهم است.دیتا بیس Nebula Graph یک پایگاه داده گراف منبع باز، توزیع شده، به راحتی مقیاس پذیر و native است. شرکت Vesoft، سازنده Nebula Graph، در رتبه هشتم، قبل از Bytedance مادر TikTok، و تنها یک جایگاه پس از هواوی قرار دارد.
هسته Nebula Graph
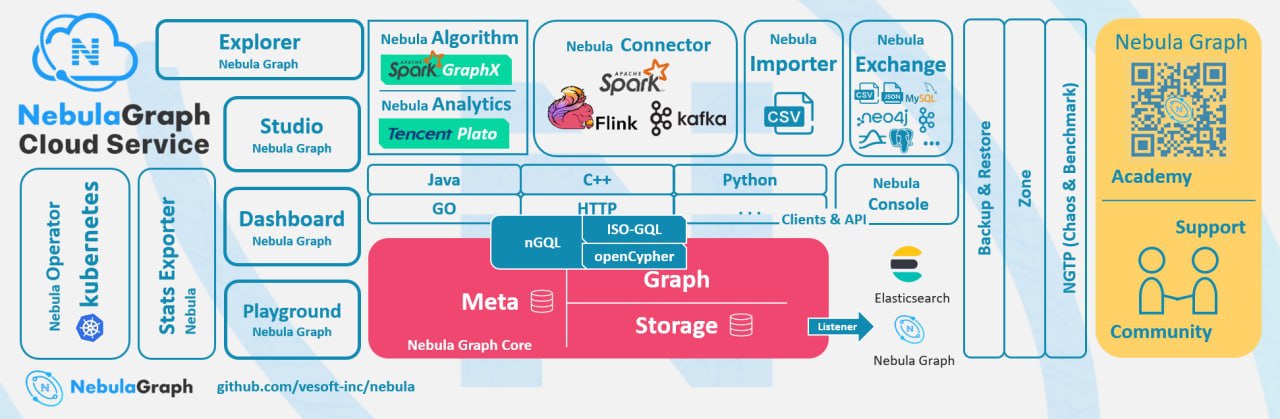
این تصویر اکوسیستم Nebula Graph را نشان می دهد که بخش قرمز رنگ، هسته Nebula Graphاست و از سه بخش متا، گراف و ذخیرهسازی تشکیل شده است.
زبان پرس و جو Nebula Graph
زبان پرس و جو nGQL است که با openCypher نیز سازگار است. ما همچنین کلاینت هایی را به زبان هایی از جمله جاوا، C++، Python و Go توسعه داده ایم. سپس در بالا تعدادی SDK داریم که می توانند با فریم ورک هایی مانند Spark، Flink، GraphX، Tencent Plato کار کنند.
معماری Nebula Graph
هسته اصلی پایگاه داده Nebula Graph از سه سرویس تشکیل شده است:
1- Graph Service
2-Storage Service
3-Meta Service
هر سرویس دارای فایل باینری اجرایی خاص خود است. این فایلها میتوانند بر روی یک مجموعه میزبان یا بر روی میزبانهای مختلف مستقر شوند.
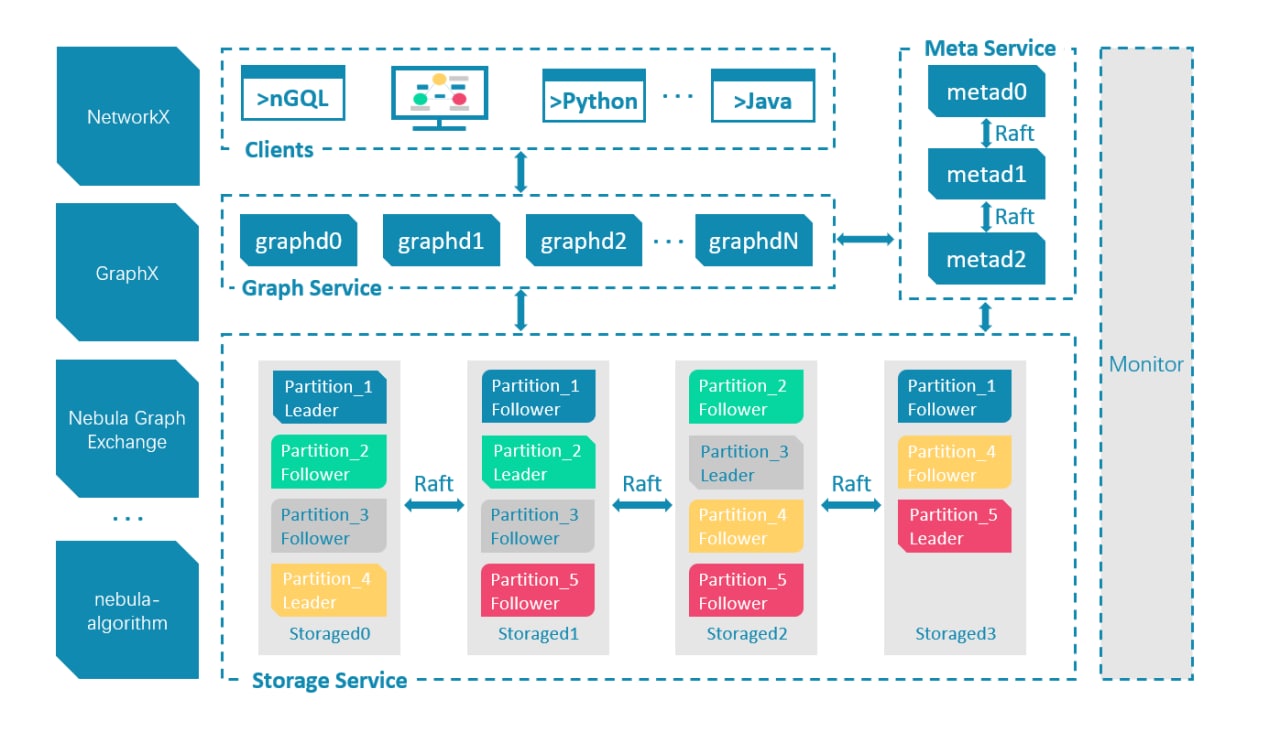
این تصویر معماری یک خوشه Nebula Graph معمولی را نشان می دهد.
سرویس Meta با ابرداده سروکار دارد، در حالی که سرویس Storage، داده ها را ذخیره می کند و سرویس Graph وظیفه پرس و جو را بر عهده دارد. این سه ماژول بر روی فرآیندهای مستقل خود اجرا می شوند و از جداسازی محاسبات و ذخیره سازی اطمینان حاصل می کنند.
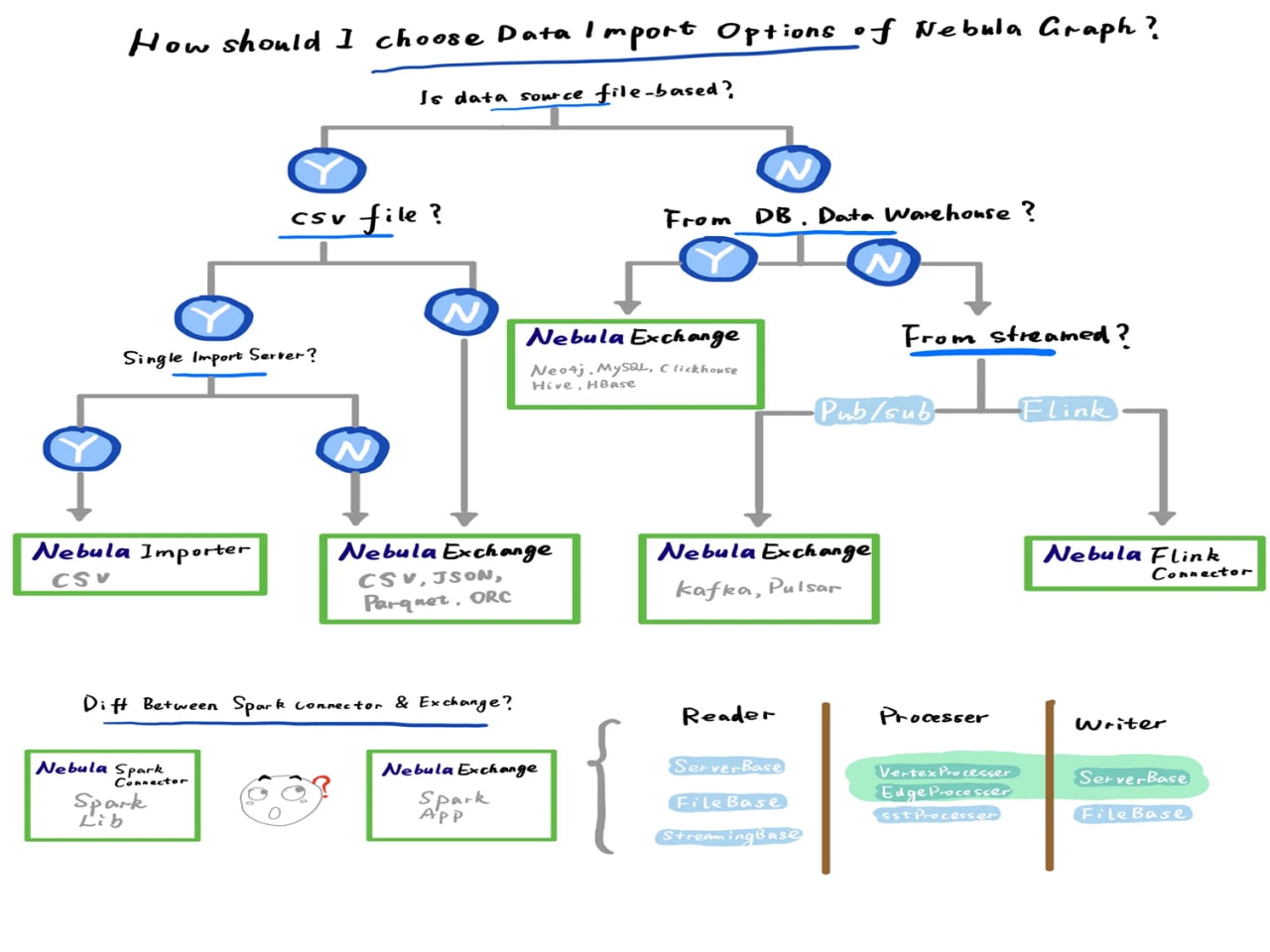
انواع روش های ورود داده Nebula Graph
دیتابیس Nebula Graph از ElasticSearch برای نمایه متن کامل استفاده می کند. از نسخه Nebula Graph v2.x، عملکرد نوشتن قابلیت نمایه سازی Nebula را بهینه کرده است.
از نسخه 2.5.0، Nebula Graph شروع به پشتیبانی از ترکیب TTL انقضای داده و نمایه سازی کرده است. و از نسخه 2.6.0، Nebula Graph شروع به پشتیبانی از عملکرد TOSS (Transaction on Storage) برای دستیابی به سازگاری نهایی لبه ها کرد.به این معنا که لبه ها یا با موفقیت نوشته می شوند یا در همان زمان با درج یا اصلاح شکست می خورند.
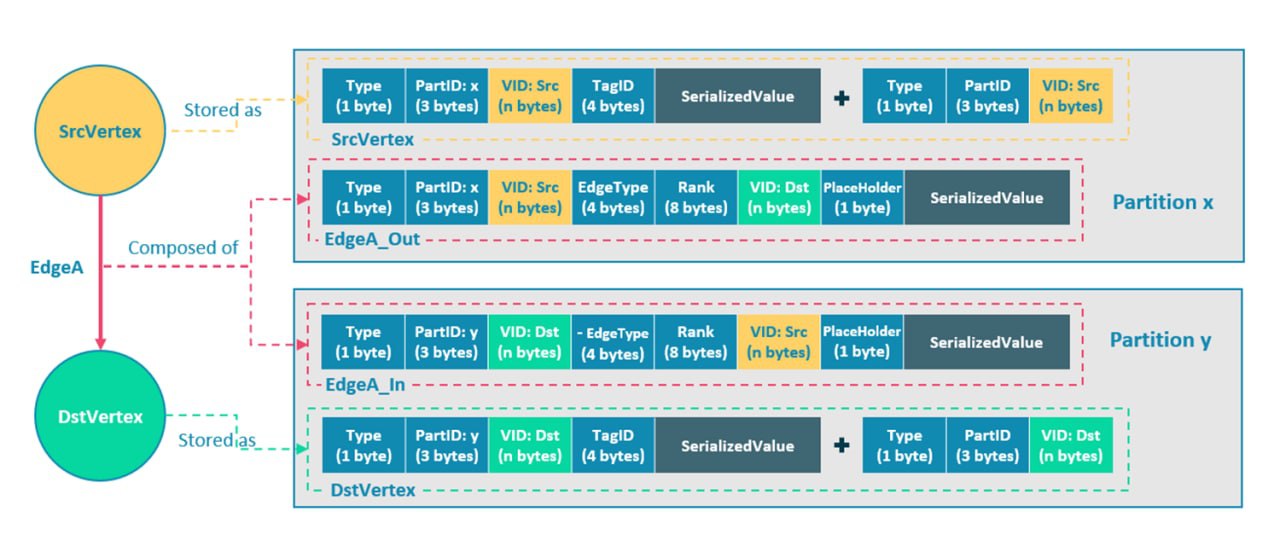
مدل داده در Nebula Graph
پایگاه داده Nebula Graph میتواند دادههایی را با تریلیونها راس و یال مدیریت کند. این بدان معنی است که سیستم باید داده ها را در ذخیره سازی و مدیریت تقسیم بندی کند. Nebula Graph از تقسیم بندی لبه ها استفاده می کند و رئوس را در پارتیشن ها ذخیره می کند. هر پارتیشن ممکن است چند کپی داشته باشد و بر روی ماشین های مختلف اجرا شود.
موتور پرس و جو بدون حالت است، به این معنی که تمام داده های پرس و جو باید یا از سرویس متا یا سرویس ذخیره سازی بازیابی شوند و هیچ ارتباطی بین سرویس های پرس و جو وجود ندارد.
موارد فوق در مورد جدایی محاسبات و ذخیره سازی توسط Nebula Graph است. حالا بیایید در مورد ویژگی های داده صحبت کنیم. اشاره کردیم که Nebula Graph یک پایگاه داده بدون طرحواره نیست و تمام داده های ذخیره شده توسط زبان های تعریف داده (DDL) از پیش تعریف شده است.
رئوس با استفاده از یک 2 تایی متشکل از vid و تگ تعریف می شوند. یال ها با استفاده از یک 4 تایی متشکل از نقاط پایانی، EdgeType و رتبه تعریف می شوند.
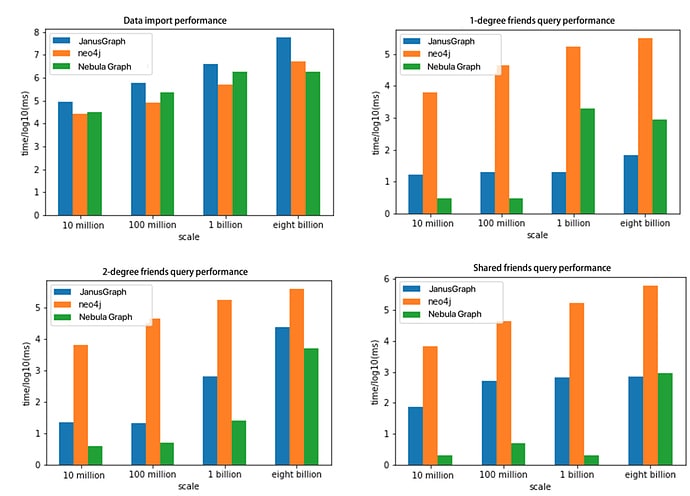
مقایسه Nebula Graph درحجم های میلیاردی
از نظر ورود داده، Nebula Graph کمی کندتر از Neo4j است که اندازه داده کوچک است. با این حال، زمانی که اندازه داده بزرگ است، Nebula Graph بسیار سریعتر از دو مورد دیگر است. برای سه جستار نمودار، Nebula Graph عملکرد بهتری را در مقایسه با Neo4j و HugeGraph نشان می دهد.
نمودارهای زیر این مقایسه ها را نمایش میدهد:
مزایای NebulaGraph
-متن باز
NebulaGraph تحت مجوز Apache 2.0 باز است. افراد بیشتری مانند توسعه دهندگان پایگاه داده، دانشمندان داده، کارشناسان امنیتی و مهندسان الگوریتم در طراحی و توسعه NebulaGraph شرکت می کنند. برای پیوستن به منبع کدها، در صفحه NebulaGraph GitHub وارد شوید.
-عملکرد فوق العاده
NebulaGraph که با زبان ++C نوشته شده و برای نمودارها متولد شده است، پرس و جوهای گراف را در میلی ثانیه مدیریت می کند. در میان اکثر پایگاه های داده، NebulaGraph عملکرد برتر در ارائه خدمات داده های نموداری را نشان می دهد. هرچه اندازه داده بزرگتر باشد، برتری NebulaGraph بیشتر است. برای اطلاعات بیشتر، به بنچمارک NebulaGraph مراجعه کنید.
-مقیاس پذیری بالا
NebulaGraph در یک معماری shared-nothing طراحی شده است و مقیاس بندی بسیار بالا و بدون وقفه در سرویس پایگاه داده را پشتیبانی می کند.
-توسعه دهنده پسند
NebulaGraph از کلاینتهای زبانهای برنامهنویسی محبوب مانند Java، Python، C و Go پشتیبانی میکند و موارد دیگر در دست توسعه هستند.
-کنترل دسترسی قابل اعتماد
NebulaGraph از کنترل دسترسی مبتنی بر نقش و سرورهای احراز هویت خارجی مانند سرورهای LDAP (Lightweight Directory Access Protocol) برای افزایش امنیت داده ها پشتیبانی می کند. برای اطلاعات بیشتر، احراز هویت و مجوز را ببینید.
-اکوسیستم متنوع
ابزارهای بومی بیشتری از NebulaGraph منتشر شده است، مانند NebulaGraph Studio، NebulaGraph Console و NebulaGraph Exchange. برای اطلاعات بیشتر در مورد ابزارهای اکوسیستم، به نمای کلی ابزارهای اکوسیستم مراجعه کنید.
علاوه بر این، NebulaGraph توانایی ادغام با بسیاری از فناوریهای پیشرفته مانند Spark، Flink و HBase را برای تقویت در دنیایی با چالشها و شانسهای فزاینده دارد.
-زبان پرس و جو سازگار با OpenCypher
زبان بومی NebulaGraph Query، همچنین به عنوان nGQL شناخته می شود، یک زبان پرس و جوی متنی باز و سازگار با OpenCypher است. درک و استفاده از آن آسان است. برای اطلاعات بیشتر، راهنمای nGQL را ببینید.
-سخت افزار آینده نگر با خواندن و نوشتن متعادل
درایوهای حالت جامد عملکرد بسیار بالایی دارند و ارزان تر می شوند. NebulaGraph محصولی مبتنی بر SSD است. در مقایسه با محصولات مبتنی بر HDD و حافظه بزرگ، برای روندهای سخت افزاری آینده مناسب تر است و دستیابی به خواندن و نوشتن متعادل، آسان تر است.
-مدل سازی داده آسان و انعطاف پذیری بالا
شما به راحتی می توانید داده های متصل را به NebulaGraph برای کسب و کار خود مدل کنید بدون اینکه آنها را در ساختاری مانند جدول رابطه ای مجبور کنید و ویژگی ها را می توان آزادانه اضافه، به روز و حذف کرد.
-محبوبیت بالا
NebulaGraph توسط رهبران فناوری مانند Tencent، Vivo، Meituan و JD Digits استفاده می شود.
«ملیحه ایزی»، فارغالتحصیل مقطع کارشناسی ارشد مهندسی کامپیوتر، گرایش نرم افزار است.