4 مفهوم پیشرفته SQL که در سال 2022 باید بدانید

- تیر 11, 1401
- 0
- ملیحه ایزی
SQL چیست؟
sql یا زبان پرس و جوی ساختاریافته، محبوبترین و رایجترین زبان برای کار با پایگاه داده است که محدود به زبان برنامه نویسی خاصی نیست، این بدان معناست که اکثر برنامهنویسها برای ارتباط با پایگاه داده به این زبان نیاز دارند. با افزایش حجم داده ها، نیاز متخصصان به کار با داده ها در حال افزایش است. فقط دانش مفاهیم پیشرفته SQL کافی نیست و شما باید بتوانید آنها را در محل کار خود به طور موثر پیاده سازی کنید و این همان چیزی است که در مصاحبه های شغلی نیز مورد نیاز است! بنابراین، من در اینجا 4 مفهوم پیشرفته SQL را با توضیحات و نمونه های پرس و جو لیست کرده ام.
· Common Table Expressions (CTEs) · ROW_NUMBER() vs RANK() vs DENSE_RANK() · CASE WHEN Statement · Extract Data From Date — Time Columns 1-Common Table Expressions (CTEs)
در حین کار با داده های دنیای واقعی، گاهی اوقات لازم داریم که یک پرس و جو را بر روی نتایج حاصل از یک پرس و جوی دیگر اعمال کنیم. یک راه ساده برای رسیدن به این هدف استفاده از sub-query ها است. اما با افزایش پیچیدگی، محاسبات و دیباگ دشوار روبرو هستیم. برای ساده تر سازی ای موضوع میتوانیم از CTE ها استفاده کنیم. CTE نوشتن و نگهداری پرس و جوهای پیچیده را آسان می کند.
✅ به عنوان مثال، استخراج داده های زیر را با استفاده از sub-query در نظر بگیرید:

در اینجا فقط از دو sub-query استفاده شده است.با افزودن محاسبات بیشتر درsub-query پیچیدگی افزایش می یابد و باعث می شود که خوانایی کد کاهش یافته و همچنین نگهداری آن نیز دشوار شود. اکنون بیایید نسخه ساده شده پرس و جو بالا را با CTE به صورت زیر ببینیم.
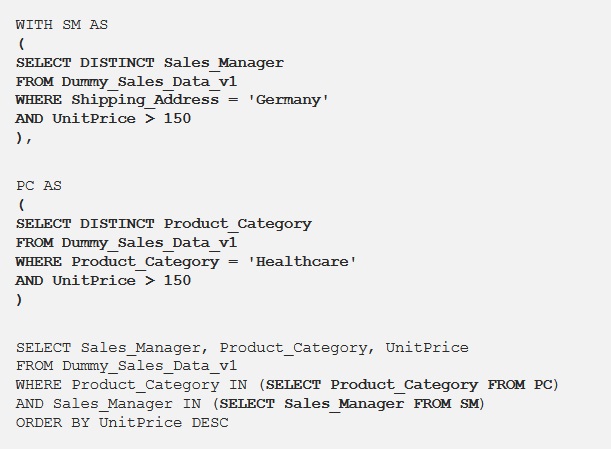
میبینیم که sub-query پیچیده به بلوک های ساده تری از کدها برای استفاده تجزیه شد. به این ترتیب، sub-query پیچیده در دو CTE SM و PC دوباره نوشته می شوند که درک و اصلاح آنها آسان تر است. CTE ها اساساً به شما این امکان را می دهد که از نتیجه یک پرس و جو یک جدول موقت ایجاد کنید. این موضوع خوانایی و نگهداری کد را بهبود می بخشد.
مجموعه داده های دنیای واقعی می توانند میلیون ها یا میلیاردها ردیف داشته باشند که 1000 گیگابایت فضای ذخیره سازی را اشغال می کنند. انجام محاسبات با استفاده از داده های این جداول و به خصوص پیوستن مستقیم آنها به جداول دیگر بسیار پرهزینه خواهد بود. راه حل نهایی برای چنین وظایفی استفاده از CTE است.
2- ROW_NUMBER() vs RANK() vs DENSE_RANK()
یکی دیگر از مفاهیم رایج مورد استفاده در هنگام کار با مجموعه داده های واقعی، رتبه بندی یا رنکینگ رکوردها است. کمپانی های مختلف در این باره از سناریوهای مختلفی استفاده می کنند:
– رتبه بندی برندهای پرفروش بر اساس تعداد فروخته شده
– رتبه بندی عمودی محصولات برتر بر اساس تعداد سفارشات یا درآمد ایجاد شده
– دریافت نام فیلم در هر ژانر با بیشترین تعداد بازدید
RANK و DENSE_RANK اساساً برای تخصیص اعداد صحیح متوالی به هر رکورد در پارتیشن ذکر شده استفاده می شوند. تفاوت بین آنها زمانی قابل مشاهده است که بین رکوردها پیوندهایی داشته باشید. رفتار و نحوه تخصیص اعداد صحیح به هر رکورد زمانی تغییر می کند که ردیف های تکراری در جدول حاصل وجود داشته باشد.

همانطور که می بینید، syntax برای هر سه یکسان است، با این حال خروجی های مختلف زیر را به همراه دارد:
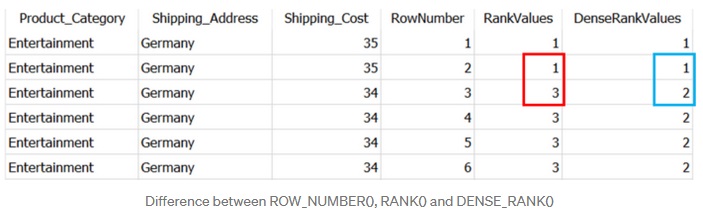
RANK : این تابع مشابه تابع ROW_NUMBER عمل میکند و میتواند کنارهر رکورد از جدول یک شماره اختصاصی قرار دهد. اگر عمل پارتیشن بندی اتفاق بیفتد ابتدای هر پارتیشن را از آخرین عدد مورد استفاده یکی اضافه میکند و شماره گذاری میکند. نکته مهم در Rank این است که فیلدی که براساس آن عمل مرتب سازی انجام میشود معیار سنجش میباشد. اگر برای چند رکورد مقدار یکسان داشته باشد حتما شماره آنها یکسان است و اگر یکسان نبود متغیر است.
ردیف های رتبه بندی شده را بر اساس شرط ORDER BY بازیابی می کند. همانطور که می بینید بین دو سطر اول یک تساوی وجود دارد، یعنی دو سطر اول در ستون Shipping_Cost ارزش یکسانی دارند (که در بند ORDER BY ذکر شده است).
RANK یک عدد صحیح را به هر دو ردیف اختصاص می دهد. با این حال، تعداد ردیف های تکرار شده را به رتبه تکراری اضافه می کند تا رتبه ردیف بعدی را بدست آورد. به همین دلیل است که در ردیف سوم (که با رنگ قرمز مشخص شده است)، RANK رتبه 3 را اختصاص می دهد (2 ردیف تکراری + 1 رتبه تکراری)
DENSE_RANK : مشابه RANK است، اما از هیچ عددی رد نمیشود، حتی اگر بین ردیفها تساوی وجود داشته باشد. این را می توانید در کادر آبی در تصویر بالا مشاهده کنید. اگر رکوردها در هر پارتیشن مقادیر یکسانی داشته باشند، رتبههای یکسانی را دریافت میکنند.
برخلاف دو مورد بالا، ROW_NUMBER به سادگی اعداد ترتیبی را به هر رکورد در پارتیشن اختصاص میدهد. اگر دو مقدار یکسان را در یک پارتیشن شناسایی کند، اعداد رتبهبندی متفاوتی را به هر دو اختصاص میدهد.
3- CASE WHEN Statement
دستور CASE به شما امکان می دهد if-else را در SQL پیاده سازی کنید، بنابراین می توانید از آن برای اجرای پرس و جو به صورت شرطی استفاده کنید. دستور CASE اساساً شرایط ذکر شده در عبارت WHEN را آزمایش می کند و مقدار ذکر شده در عبارت THEN را برمی گرداند. وقتی هیچ شرطی برآورده نشد، مقدار ذکر شده در بند ELSE را برمی گرداند.
هنگام کار بر روی داده واقعی، دستور CASE اغلب برای دسته بندی داده ها بر اساس مقادیر در ستون های دیگر استفاده می شود. همچنین می توان از آن در کنار توابع جمع استفاده کرد.
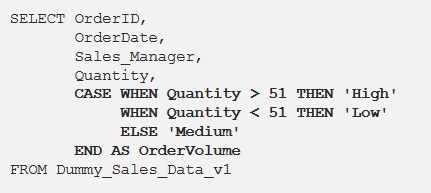
می بینیم که در خروجی یک ستون جدید OrderVolume ایجاد شده است و بسته به مقادیر در ستون Quantity، مقادیری به عنوان “High”، “Low”، “Medium” اضافه شده است.
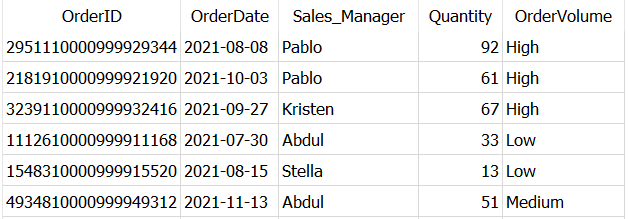
– می توانید از چندین عبارت WHEN..THEN در کنار هم استفاده کنید.
– اگر بند ELSE را ذکر نکردید و یا هیچ شرطی برآورده نشد، کوئری برای آن رکورد خاص، NULL را برمیگرداند.
گاهی اوقات داده هایی که با آنها سر و کار دارید در قالب (تعداد ردیف > تعداد ستون) هستند و باید آنها را در قالب (تعداد ستون ها > تعداد ردیف ها) دریافت کنید. در این موارد نیز دستور case کاربرد دارد.
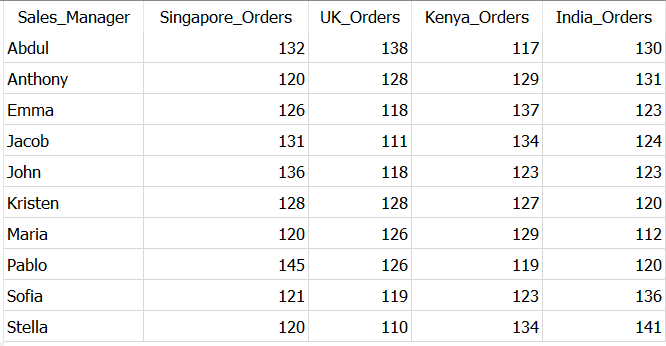
به عنوان مثال، بیایید بررسی کنیم هر مدیر فروش برای سنگاپور، بریتانیا، کنیا و هند چند سفارش انجام داده است.

با استفاده از CASE..WHEN..THEN ستون های جداگانه ای برای هر یک از آدرس های حمل و نقل ایجاد کردیم و خروجی به صورت زیر است.
4- Extract Data From Date — Time Columns
فرض کنید به تاریخ خاص نیاز دارید مثلا روزهایی در ماه که فروش انجام شده است اما ستون مشخص و جدایی برای تاریخ نداریم در این حالت شما باید داده را از ستونهای دیگر خارج کنید.

انواع توابع تاریخ و زمان درsql server:
CURRENT_TIMESTAMP: تاریخ و زمان را تا میلی ثانیه برمیگرداند.
GETUTCDATE: تاریخ و زمان را تا میلی ثانیه برمیگرداند.
GETDATE: تاریخ و زمان سیستم را برمیگرداند.
SYSDATETIME: برای برگرداندن تاریخ و زمان رایانه ای که در حال حاضر SQL Server در آن کار می کند استفاده میشود.
SYSUTCDATETIME: تاریخ و زمان را برحسب ساعت جهانی را برمیگرداند.
DATENAME: بخشی از تاریخ و زمان را به صورت رشته برمیگرداند.
DATEPART: بخشی از تاریخ و زمان را به صورت عددی برمیگرداند.
DAY: روز را برمیگرداند.
MONTH: ماه را برمیگرداند.
YEAR: سال را برمیگرداند.
DATEADD: به تاریخ اضافه میکند.
DATEDIFF: اختلاف بین دو تاریخ را برمیگرداند.
ISDATE: چک میکند یک داده از نوع تاریخ است یا نه.
SWITCHOFFSET: اختلاف ساعت را از بعد جغرافیایی برمیگرداند.
EOMONTH: آخرین روز ماه را برمیگرداند.
«ملیحه ایزی»، فارغالتحصیل مقطع کارشناسی ارشد مهندسی کامپیوتر، گرایش نرم افزار است.